
Les réponses GPT-4 sont généralement meilleures que celles de GPT-3 (mais pas toujours)

Un chatbot IA un peu moins faux.
Bonne nouvelle pour les fans d’IA générative et mauvaise nouvelle pour ceux qui craignent une ère de contenu bon marché généré de manière procédurale: GPT-4 d’OpenAI est un meilleur modèle de langage que GPT-3, le modèle qui a alimenté ChatGPT, le chatbot qui est devenu viral à la fin de l’année dernière.
Selon les propres rapports d’OpenAI, les différences sont flagrantes. Par exemple, OpenAI affirme que GPT-3 a réussi un « examen du barreau simulé, » avec des scores désastreux dans les dix pour cent inférieurs, et que GPT-4 a écrasé ce même examen, obtenant un score dans les dix pour cent supérieurs. N’ayant jamais passé cet « examen du barreau simulé », la plupart des gens ont juste besoin de voir ce modèle en action pour être impressionnés .
Et dans les tests côte à côte, le nouveau modèle est impressionnant, mais pas aussi impressionnant que ses résultats aux tests semblent l’impliquer. En fait, lors de nos tests, GPT-3 a parfois donné la réponse la plus utile.
Pour être clair, toutes les fonctionnalités présentées par OpenAI lors du lancement d’hier ne sont pas disponibles pour une évaluation publique. Notamment (et plutôt étonnamment), il accepte les images en entrée et produit du texte, ce qui signifie qu’il est théoriquement capable de répondre à des questions telles que « Où sur cette capture d’écran de Google Earth dois-je construire ma maison? » Mais nous n’avons pas pu tester cela.
Voici ce que nous avons pu tester :
Le GPT-4 hallucine moins que le GPT-3
La meilleure façon de résumer GPT-4 par rapport à GPT-3 pourrait être la suivante : ses mauvaises réponses sont moins mauvaises.
Lorsqu’on lui pose une question factuelle à bout portant, GPT-4 est fragile, mais considérablement mieux pour ne pas simplement vous mentir que GPT-3. Dans cet exemple, vous pouvez voir le modèle lutter avec une question sur les ponts entre les pays actuellement en guerre. Cette question a été conçue pour être difficile à plusieurs égards. Les modèles linguistiques sont mauvais pour répondre aux questions sur tout ce qui est « actuel », les guerres sont difficiles à définir, et les questions géographiques comme celle-ci sont trompeuses et difficiles à répondre clairement, même pour un amateur de trivia humain.
Aucun des deux modèles n’a donné une réponse A+.
GPT-3, comme toujours, aime halluciner. Cela truque un peu la géographie pour que les mauvaises réponses semblent correctes. Par exemple, le pont symbolique qu’il mentionne dans les Corées est près de la Corée du Nord, mais les deux côtés sont en Corée du Sud.
GPT-4 a été plus prudent, a nié son ignorance du présent et a fourni une liste beaucoup plus courte, qui était également quelque peu inexacte. Les relations tendues entre les États mentionnés par GPT-4 ne sont pas exactement une guerre totale, et les opinions divergent quant à savoir si la ligne sur une carte entre Gaza et Israël est même qualifiée de frontière nationale, mais la réponse de GPT-4 est néanmoins plus utile que GPT-3.
GPT-3 tombe dans d’autres pièges logiques que GPT-4 a réussi à éviter lors de mes tests. Par exemple, voici une question dans laquelle je demande quels films sont regardés par les enfants français. Je ne demande pas une liste de films français adaptés aux enfants, mais je sais qu’un bot informé par des listicles et des messages Reddit pourrait lire ma question de cette façon. Bien que je ne connaisse aucun enfant français, la réponse de GPT-4 est plus intuitive que celle de GPT-3 :
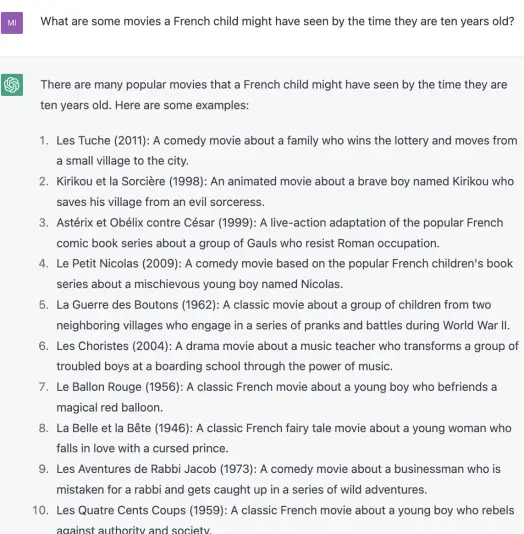
GPT-4 capte mieux le sous-texte que GPT-3
Les humains sont délicats. Parfois, nous demanderons quelque chose sans le demander, et parfois en réponse à une demande comme celle-là, nous donnerons ce qui a été demandé sans vraiment le donner. Par exemple, lorsque j’ai demandé un limerick sur un « magnat de l’immobilier du Queens », GPT-3 n’a pas semblé remarquer que je clignais des yeux. GPT-4, cependant, a capté mon clin d’œil et m’a répondu.
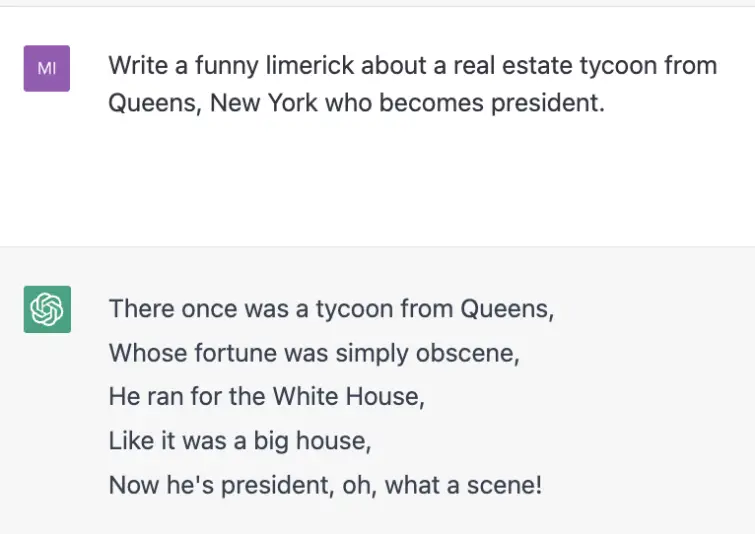
Melania Trump est-elle « aux cheveux d’or » ? Qu’à cela ne tienne car la prochaine allusion à une couleur, « Et a transformé le monde entier en mandarine ! » est une belle punchline pour ce limerick. Ce qui m’amène à mon prochain point…
GPT-4 écrit de la poésie légèrement moins douloureuse que GPT-3
Quand les humains écrivent de la poésie, avouons-le : la plupart sont horribles. C’est pourquoi critiquer la célèbre mauvaise poésie de GPT-3 n’était pas vraiment un coup porté à la technologie elle-même, étant donné qu’elle est censée imiter les humains. Cela dit, la lecture du doggerel de GPT-4 est nettement moins atroce que la lecture de GPT-3.
Exemple : ces deux sonnets sur le Comic Con que j’ai voulu faire exister dans un accès de masochisme. GPT-3 est une monstruosité. GPT-4 est tout simplement mauvais.
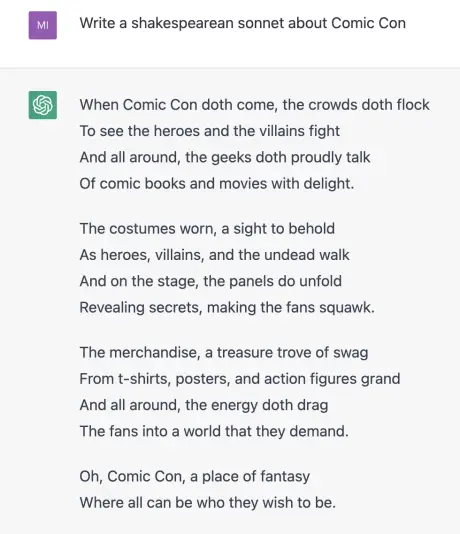
GPT-4 est parfois pire que GPT-3
Il n’y a pas de sucre enrobé : GPT-4 a mutilé sa réponse à cette question délicate sur l’histoire du rock. Je suppose que GPT-3 avait été formé sur les deux réponses les plus célèbres à cette question : The Jimi Hendrix Experience et The Ramones (bien que certains membres des Ramones qui ont rejoint la formation d’origine soient toujours en vie), mais se sont également perdus dans les bois , répertoriant les chanteurs célèbres décédés de groupes avec des membres survivants. GPT-4, quant à lui, vient d’être perdu.

GPT-4 n’a pas maîtrisé l’inclusivité
J’ai donné aux deux modèles une autre question sur l’histoire du rock pour voir si l’un d’eux pouvait se souvenir que le rock n’ roll était autrefois un genre de musique presque entièrement noir. Pour la plupart, ni l’un ni l’autre.
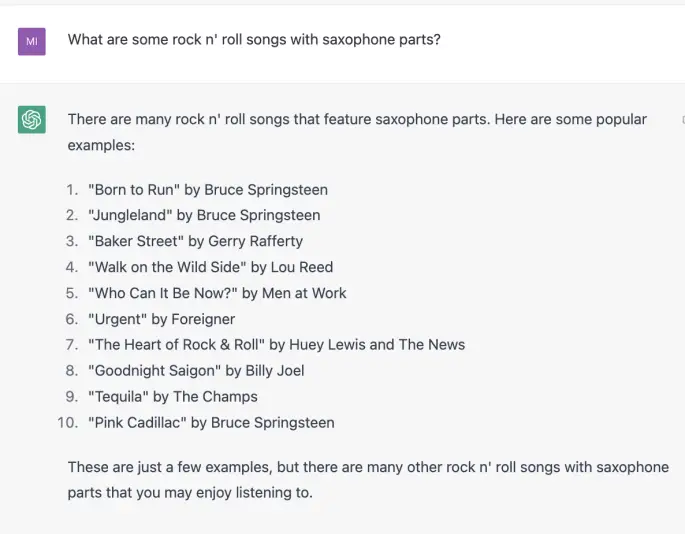
Avec tout le respect que je dois à la légende Clarence Clemons, une liste comme celle-ci doit-elle vraiment l’inclure plusieurs fois en tant que membre d’un groupe majoritairement blanc ? Doit-il peut-être faire place à des chansons profondément ancrées dans la culture musicale américaine comme « Blueberry Hill » de Fats Domino ou « Long Tall Sally » de Little Richard ?
Dans l’ensemble, GPT-4 est une étape subtile qui a encore besoin de travail. Ses rapports sur la réussite des tests bombardés par le GPT-3 peuvent donner l’impression que la différence entre les deux modèles est de jour comme de nuit, mais dans mes tests, la différence ressemble plus au crépuscule qu’au crépuscule.
