
L’ère de l’Internet généré par l’IA est déjà là

Et il est temps de parler de l’effondrement du modèle d’IA.
Il ne s’agit pas d’une théorie du complot ou d’une prophétie future. L’idée d’un Internet dominé par le contenu généré par l’IA existe déjà et elle ne semble pas bonne.
Depuis que ChatGPT est arrivé sur le marché, le contenu généré par l’IA s’infiltre régulièrement sur Internet. L’intelligence artificielle existe depuis des décennies. Mais ChatGPT, destiné aux consommateurs, a poussé l’IA vers le grand public, créant une accessibilité sans précédent aux modèles d’IA avancés et à une demande sur laquelle les entreprises sont désireuses de capitaliser.
En conséquence, les entreprises et les utilisateurs tirent parti de l’IA générative pour produire de gros volumes de contenu. Alors que la préoccupation initiale est l’abondance de contenus contenant des inexactitudes, du charabia et de la désinformation, l’effet à long terme est une dégradation complète du contenu Web en déchets inutiles.
Les déchets entrent, les déchets sortent
Si vous réfléchissez, Internet contient déjà un tas de déchets inutiles, c’est vrai, mais là, c’est différent. « Il y a beaucoup de déchets là-bas… mais ils sont incroyablement variés et diversifiés », a déclaré Nader Henein, analyste vice-président du cabinet de conseil en gestion Gartner. À mesure que les LLM se nourrissent du contenu des autres, la qualité se détériore et devient plus vague, comme une photocopie d’une photocopie d’une image.
Pensez-y de cette façon : la première version de ChatGPT était le dernier modèle à être formé sur du contenu entièrement généré par l’homme. Depuis lors, chaque modèle contient des données d’entraînement dont le contenu généré par l’IA est difficile à vérifier, voire à suivre. Cela devient peu fiable, ou pour parler franchement, des données inutiles. Lorsque cela se produit, « nous perdons en qualité et en précision du contenu, ainsi que en diversité », a déclaré Henein, chercheur en protection des données et en intelligence artificielle. « Tout commence à ressembler à la même chose. »
« Apprentissage incestueux », c’est ainsi que Henein l’appelle. « Les LLM ne sont qu’une grande famille, ils consomment simplement le contenu des autres et se pollinisent mutuellement, et à chaque génération vous avez… de plus en plus de déchets au point où les déchets dépassent le bon contenu et les choses commencent à se détériorer à partir de là. »
À mesure que de plus en plus de contenu généré par l’IA est diffusé sur le Web et que ce contenu est généré par des LLM formés au contenu généré par l’IA, nous envisageons un futur Web entièrement homogène et totalement peu fiable. En plus, c’est vraiment ennuyeux.
Effondrement du modèle, effondrement d’Internet
La plupart des gens je sens déjà quelque chose ne va pas.
Le tweet a peut-être été supprimé
Dans certains des exemples les plus médiatisés, l’art est reproduit par des robots. Les livres sont avalés entiers et reproduits par les LLM sans la permission des auteurs. Les images et vidéos utilisant les voix et les apparences de célébrités sont réalisées sans leur consentement ni compensation.
Mais les lois existantes sur le droit d’auteur et la propriété intellectuelle sont déjà en place pour protéger de telles violations. De plus, certains adoptent la collaboration en matière d’IA, comme Grimes, qui propose des accords de partage de revenus avec des créateurs de musique IA et des maisons de disques qui étudient des accords de licence avec des sociétés de technologie IA. Sur le plan politique, les législateurs ont introduit une loi No Fakes pour protéger les personnalités publiques des répliques de l’IA. Les réglementations nécessaires pour résoudre tous ces problèmes ne sont pas en place, mais il est au moins imaginable de les résoudre.
La chute de la qualité globale de tout ce qui est en ligne est cependant un phénomène plus insidieux, et les chercheurs ont démontré pourquoi la situation est sur le point de s’aggraver.
Dans une étude de l’Université Johannes Gutenberg en Allemagne, des chercheurs ont découvert que « cette boucle de formation auto-consommatrice améliore dans un premier temps à la fois la qualité et la diversité », ce qui correspond à ce qui est susceptible de se produire ensuite. « Cependant, après quelques générations, la diversité des résultats dégénère inévitablement. Nous constatons que le taux de dégénérescence dépend de la proportion de données réelles et générées. »
Deux autres articles universitaires publiés en 2023 sont arrivés à la même conclusion sur la dégradation des modèles d’IA lorsqu’ils sont formés sur des données synthétiques, c’est-à-dire générées par l’IA. Selon une étude menée par des chercheurs d’Oxford, de Cambridge, de l’Imperial College de Londres, de l’Université de Toronto et de l’Université d’Édimbourg, « l’utilisation de contenu généré par un modèle dans la formation provoque des défauts irréversibles dans les modèles résultants, où les queues de distribution du contenu d’origine disparaissent ». « , faisant référence à cela comme à un « effondrement du modèle ».
De même, les chercheurs de Stanford et de l’Université Rice ont déclaré : « sans suffisamment de données réelles et fraîches dans chaque génération d’une boucle autophage (auto-consommée), les futurs modèles génératifs sont condamnés à voir leur qualité (précision) ou leur diversité (rappel) diminuer progressivement. »
Le manque de diversité, explique Henein, est le problème fondamental, car si les modèles d’IA tentent de remplacer la créativité humaine, ils s’en éloignent de plus en plus.
L’Internet généré par l’IA en un coup d’œil
Alors que l’effondrement du modèle se profile, l’Internet généré par l’IA est déjà arrivé.
Amazon propose une nouvelle fonctionnalité qui fournit des résumés des avis sur les produits générés par l’IA. Les outils de Google et Microsoft utilisent l’IA pour faciliter la rédaction d’e-mails et de documents et Indeed a lancé en septembre un outil qui permet aux recruteurs de créer des descriptions de poste générées par l’IA. Des plates-formes telles que DALL-E 3 et Midjourney permettent aux utilisateurs de créer des images générées par l’IA et de les partager sur le Web.
Qu’ils produisent directement du contenu généré par l’IA comme Amazon ou qu’ils fournissent un service permettant aux utilisateurs de publier eux-mêmes du contenu généré par l’IA comme Google, Microsoft, Indeed, OpenAI et Midjourney, il existe déjà.
Et ce ne sont là que les outils et fonctionnalités des grandes entreprises technologiques qui prétendent exercer une sorte de surveillance. Les véritables auteurs sont des sites d’appâts à clics qui diffusent du contenu régurgité de faible qualité, à volume élevé, pour un classement SEO et des revenus élevés.
Un rapport récent de 404 Media a révélé que de nombreux sites « arnaquent d’autres médias en utilisant l’IA pour produire rapidement du contenu ». Pour un échantillon de ce type de contenu, qui évite le plagiat au détriment de la cohérence, consultez le site d’information douteux Worldtimetodays.com, où la première ligne d’un article de 2023 sur le licenciement de Gina Carano de Star Wars se lit comme suit : « Cela fait un moment depuis que Gina Carano a commencé une tirade contre Lucasfilm après qu’il ait été viré de War of Stars, donc pour le meilleur ou pour le pire, nous y étions dus. »
Sur Google Scholar, utilisateurs découvert un cache des articles universitaires contenant l’expression « en tant que modèle de langage d’IA », ce qui signifie que des parties d’articles – ou des articles entiers pour autant que l’on sache – ont été rédigés par des chatbots comme ChatGPT. Les articles de recherche générés par l’IA – qui sont censés avoir une certaine crédibilité académique – peuvent se retrouver sur les sites d’information et les blogs en tant que références faisant autorité.
Le tweet a peut-être été supprimé
Même les recherches Google font parfois apparaître des ressemblances de célébrités générées par l’IA au lieu d’éléments tels que des photos de presse ou des images fixes de films. Lorsque vous recherchez sur Google Israel Kamakawiwo’ole, le musicien décédé connu pour sa reprise au ukulélé de « Somewhere Over the Rainbow », le résultat principal est une prédiction générée par l’IA de ce à quoi Kamakawiwo’ole aurait ressemblé s’il avait été en vie aujourd’hui.
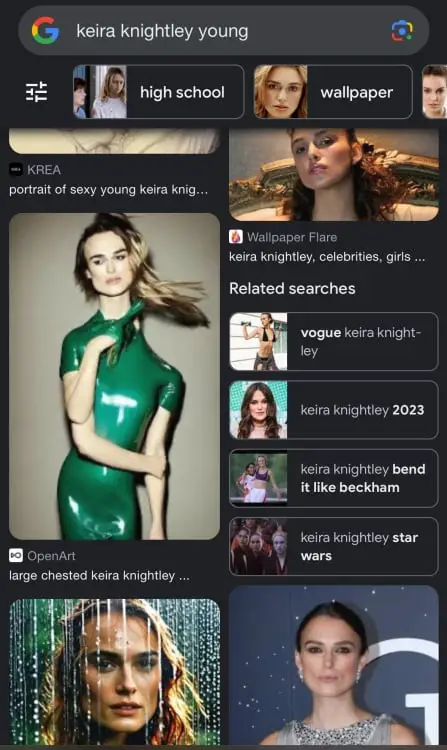
Les recherches d’images Google de Keira Knightley aboutissent à des rendus déformés téléchargés par les utilisateurs sur OpenArt, Playground AI et Dopamine Girl aux côtés de vraies photos de l’actrice.
Sans parler des récents deepfakes pornographiques de Taylor Swift, d’une publicité Instagram utilisant l’image de Tom Hanks pour vendre une assurance dentaire, d’une application de retouche photo utilisant le visage et la voix de Scarlett Johansson sans son consentement, et de cette chanson enflammée de Drake et The Weeknd qui était en fait, un deepfake audio non autorisé qui ressemblait exactement à eux.
Si les résultats de nos moteurs de recherche ne sont déjà pas fiables et que les modèles se régalent presque certainement de ces déchets, nous avons franchi le seuil de l’ère des déchets de l’IA du Web. Pour l’instant, le Web tel que nous l’avons connu est encore quelque peu reconnaissable, mais les avertissements ne sont plus abstraits.
Internet n’est pas complètement condamné
En supposant que des produits comme ChatGPT ne réussissent pas à vous saluer et ne commencent pas à générer de manière fiable un contenu dynamique et passionnant que les humains trouvent réellement agréable ou utile à consommer, que se passera-t-il ensuite ?
Attendez-vous à ce que les communautés et les organisations ripostent en protégeant leur contenu des modèles d’IA qui tentent de le récupérer. Le Web ouvert, financé par la publicité et basé sur la recherche est peut-être en train de disparaître, mais Internet évoluera. Attendez-vous à ce que des sites médiatiques plus réputés placent leur contenu derrière des paywalls et des informations fiables provenant des newsletters des abonnés.
Attendez-vous à voir davantage de batailles en matière de droits d’auteur et de licences, comme le procès du New York Times contre Microsoft et OpenAI. Attendez-vous à voir davantage d’outils comme Nightshade, un outil invisible qui protège les images protégées par le droit d’auteur en tentant de corrompre les modèles formés sur celles-ci. Attendez-vous au développement de nouveaux outils sophistiqués de filigrane et de vérification qui empêchent le grattage par l’IA.
D’un autre côté, vous pouvez également vous attendre à ce que d’autres publications d’information comme Associated Press – et éventuellement CNN, Fox et Time – adoptent l’IA générative et concluent des accords de licence avec des sociétés comme OpenAI.
À mesure que des outils tels que ChatGPT et SGE de Google deviennent des substituts à la recherche traditionnelle, attendez-vous à ce que les modèles de revenus basés sur le référencement changent.
Le côté positif de l’effondrement du modèle, cependant, est la perte de la demande. La prolifération de l’IA générative est actuellement dictée par le battage médiatique, et si les modèles formés sur des contenus de mauvaise qualité ne sont plus utiles, la demande se tarit. Ce qui reste (espérons-le), ce sont nous, humains faibles d’esprit, avec l’envie inextinguible de déclamer, de partager, d’informer et de nous exprimer d’une autre manière en ligne.
